视频也能P!谷歌CVPR 2021最新视频P图模型omnimatte
本站寻求有缘人接手,详细了解请联系站长QQ1493399855
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

来源:Google AI 、新智元
【导读】你是否还在受视频P图不能分割主体的苦?是否还在被人说P图不真实,影子都没有?谷歌在CVPR 2021发布的omnimatte将彻底解决你的烦恼,只需一键操作,视频立刻分为背景和前景主体,影子水花都能抠,多个蒙版,视频想怎么P就怎么P!
图像和视频编辑操作通常依赖于精确的蒙版(matte)操作,即分离前景和背景并能够合成图像。
虽然最新的计算机视觉技术可以为自然图像和视频生成高质量的蒙版,允许合成景深、编辑和合成图像,或者从图像中移除背景等应用场景。
但最基本的核心逻辑目前CV技术仍无法做到:也就是被遮盖或添加的物体可能在新图像中有新的场景效果,例如阴影、镜面反射或烟雾,这些通常都没有被添加到合成图像中。
这也是PS图片合成和鉴别中特别需要注意的,不然就会被人说P图太假了。
Google在CVPR 2021上发表了一篇文章,主要描述了一种新的蒙版生成方法omnimatte,能够利用分层神经渲染技术(layered neural rendering)将视频分层,能够把包括主体在内的所有环境交互的效果都给提取出来。

https://ai.googleblog.com/2021/08/introducing-omnimattes-new-approach-to.html
一般的分割模型只能够提取场景中的主体的mask,例如,一个人和一条狗,但Google提出的方法可以分离和提取与主体相关的其他细节,包括投射在地面上的阴影。

与分割遮罩(segmentation masks)不同的是,omnimatte能够捕捉部分透明的柔和效果,比如反射、飞溅或轮胎烟雾。与传统蒙版一样,omnimatte是 RGBA 图像,包括一个alpha 通道。
omnimatte可以在大部分图像或视频编辑工具进行操作,并且可以在任何使用传统蒙版的地方使用,例如,将文本插入视频中的烟迹下,效果真是牛。
为了生成omnimatte,首先将输入的视频分成一组层: 每一个层用于一个移动的主体或是用于静止的背景物体。例如下图中可以看到,有一个图层用于人,一个图层用于狗,还有一个图层用于背景,当合并在一起使用传统的阿尔法混合方法,这些层可以重新合成这个输入视频。

除了能够重新合成视频,层分解必须能够在每一层捕获正确的效果。例如,如果人的阴影出现在狗的图层中,合并后的图层虽然仍然能够重新合成输入视频,但是在人和狗之间插入一个额外的元素会产生一个明显的错误。
所以这个难点在于找到一个分解的地方,其中每个主体的层只捕捉主体的效果,从而才能产生一个真正的omnimatte。
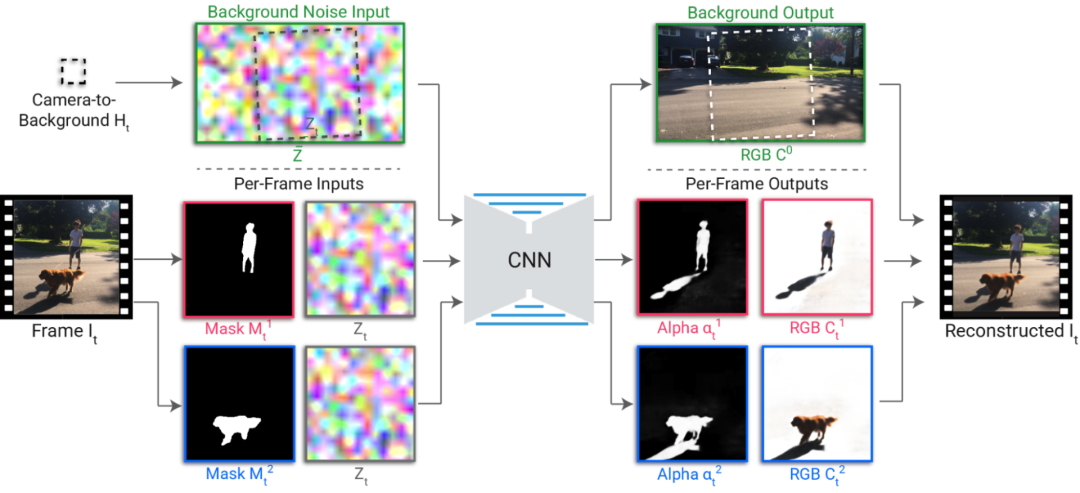
解决方案是应用Google 先前开发的分层神经渲染方法来训练一个卷积神经网络分割模板来将主体的分割遮罩和背景噪声图像映射到一个omnimatte图像中。
由于 CNN 的结构,它们很自然地倾向于学习图像效果之间的相关性,而且效果之间的相关性越强,CNN 就越容易学习。
例如在上面的视频中,人和他们的影子之间的空间关系,以及狗和它的影子之间的空间关系,在他们从右向左走的过程中保持相似。人和狗的影子或者狗和人的影子之间的关系变化更大(因此,相关性更弱)。CNN 首先学习更强的相关性,然后才能正确地分解层。
在预处理中,用户选择主体并为每个主体指定一个层。使用现成的分割网络(如 MaskRCNN)提取每个主体的分割遮罩,并使用标准的摄像机稳定工具找到相对于背景的摄像机转换。
在背景参考帧中定义随机噪声图像,并利用摄像机变换进行采样,生成每帧噪声图像。噪声图像提供是随机但一致的图像特征,随着时间的推移,能够为 CNN 学习重建背景颜色提供一个自然的输入。
渲染的 CNN 采用分割遮罩和每帧噪声图像作为输入,生成 RGB 彩色图像和 alpha 图像,用来捕获每一层的透明度。这些输出通过传统的 alpha 混合来产生输出帧。
CNN 从随机初始化权重开始训练,通过寻找并关联蒙版中未捕捉到的效果(例如阴影、反射或烟雾)与给定的前景层来重建输入帧,并确保主体的 alpha 大致包括分割蒙版。为了确保前景层只捕获前景元素而不捕获静止背景元素,在前景层 alpha 上也应用了稀疏损失(sparsity loss)。
并且还需要为每个视频训练一个新的渲染网络。由于网络只需要重建单一的输入视频,除了分离每个主体的影响,它还能够捕捉精细结构和快速运动。例如在步行的图片中,omnimatte能够捕获包括投射在公园长椅板条上的影子。

在网球的例子,网球的的小阴影,甚至网球都能够被捕获。

在足球的例子中,运动员和球的阴影被分解为合适的层,但是当运动员的脚被球挡住时有一个小的错误。

这个基本模型已经能够运行的非常666了,但是还可以通过增加 CNN 的输入来改进结果,例如增加额外的缓冲区,如光流或纹理坐标等。
omnimate的应用场景也很多,例如可以删除指定的主体,只需从合成中删除他们的层,也可以复制某个物体,也只需要在合成中复制它们的图层即可。
下图演示了如何删除和复制主体,视频已经被分解为一个omnimatte,并且马被复制了几次以产生频闪摄影效果,并且可以看到马投射在地面和障碍物上的阴影能够被正确捕捉。

一个更强大的应用场景是重新计时(retime)这个主体。时间操纵在电影中被广泛使用,但是通常需要为每个主体单独拍摄,并且有一个可控制的拍摄环境。
通过对omnimatte的分解,仅仅通过独立地改变每一层的播放速率,就可以使日常视频产生重定时效果。
由于omnimatte是标准的 RGBA 图像,这种重新定时编辑可以使用传统的视频编辑软件。
例如下面的三个主体被分解为三个层,通过简单地调整图层的回放速度,这些小孩儿最初的不同步的跳跃就能对齐,并且从水花的溅落和反射中也看不出修改的痕迹。

最后依然是道德性的说明,Google 提醒研究人员应该意识到即使是简单的重新排列也能显著改变视频的效果,并且研究人员应该对任何操作图像的技术的可能应用场景负责,因为它可能被滥用来产生虚假和误导性的信息。
omnimate目前的工作也还有改进空间,例如它要求相机的位置是固定的,并且系统只支持可以被建模为全景的背景。当摄像机位置移动时,全景模型不能准确捕捉整个背景,一些背景元素可能会打乱前景层的提取。
如果要处理通用的相机运动,如走过一个房间或街道,则需要一个3 d 背景模型。在运动物体和运动效果下重建三维场景仍然是一个困难的研究挑战。
并且理论上CNN学习相关性的能力是强大的,但仍然不可解释,某些应该能分解出来的层却无法分解,虽然现在能够人工编辑抽取,但最好的方法还是好好解决CNN的问题,提升模型。
参考资料:
努力分享优质的计算机视觉相关内容,欢迎关注:

点个在看 paper不断!